Postcopy & user-fault & WASM
Migration of WebAssembly runtime by Postcopy
User space page fault在Live migration of virtual machines已经有大量运用(KVM,OpenStack,CRIU Lazy migration),这一思路被称为Postcopy。目前尚未发现这一技术应用于WASM runtime的状态迁移。结合Mitosis的先例,或许Postcopy技术可以良好的与WASM runtime结合,从而实现可以快速大量启动实例的Serverless平台。
(目前只找到了一篇21年的论文,其中提到了他们计划结合Postcopy+wasm做边缘计算。但是他们目前还没有发表相关后续进展,不知道是因为他们没有继续深入,还是遇到了障碍)
设计方案
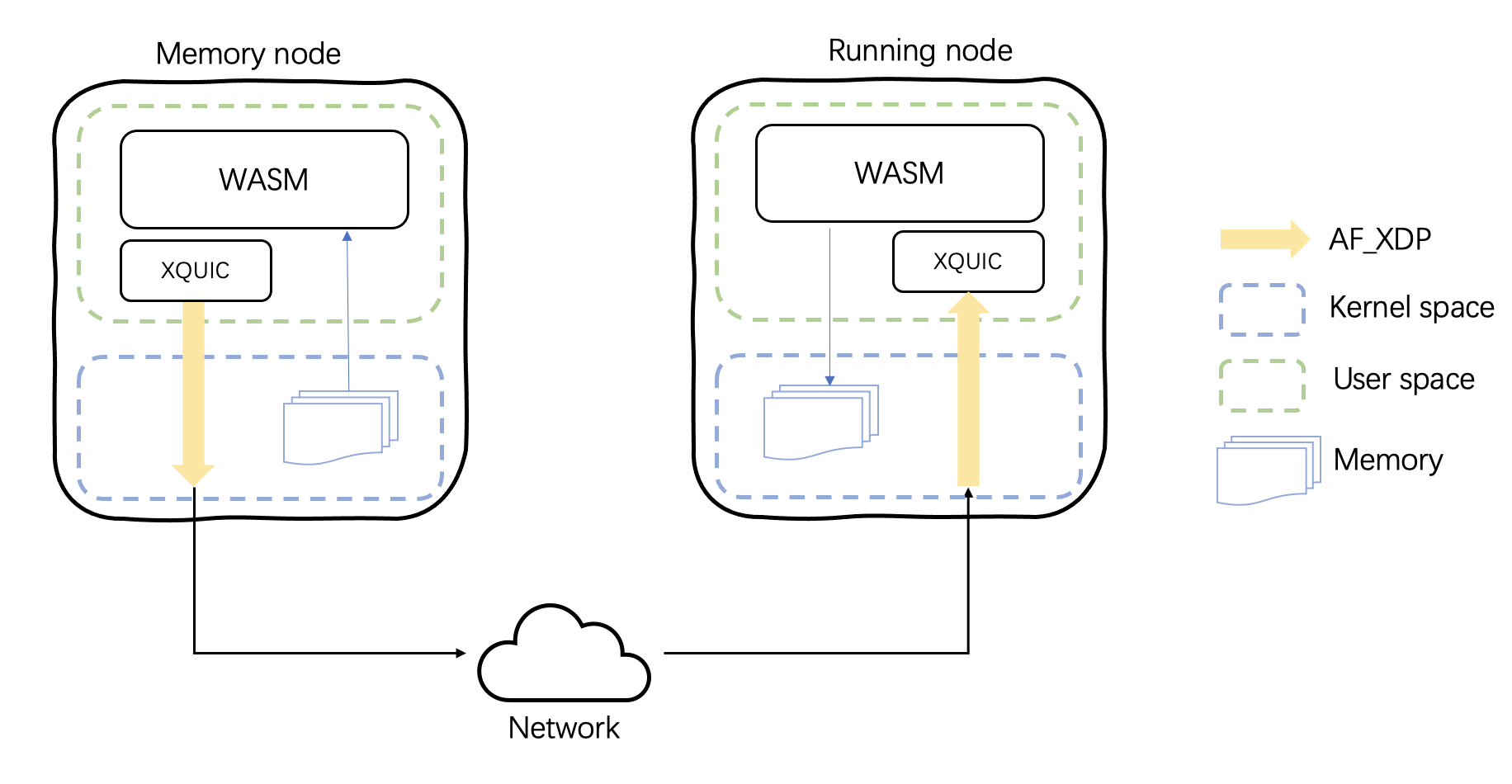
Steps:
- Running node启动,从Memory node获取除内存外的全部数据
- Running node初始化虚拟机内存(不进行映射),将这些内存标记为userfault
- Running node运行,若access到了未被分配的page,则触发page fault
- 内核识别到该页为userfault page,将发生错误的地址发送给用户态的handle
- handle使用XQUIC获取Memory node中相应的page,初始化该page
- WASM runtime被唤醒,继续运行
结合Postcopy+WASM技术,应该可以实现优于原生Faasm,优于CRIU,但慢于MITOSIS的一种启动策略。同时这一策略会比MITOSIS有更好的通用性。
此外,Postcopy+WASM比起Mitosis和CRIU这类“容器迁移”工具有一个优势,这两种技术在迁移容器的过程中,都不可避免带有一些“死重”,即容器本身运行时相关的上下文。而Postcopy+WASM只需动态迁移和程序负载本身相关的Page,因此或许可以在一定条件下取得一定优势。
Follow Up:
1.由于WASM虚拟机内,各种模块大小已知,或许可以根据这个做一些规划算法
2.将部分工作放入eBPF虚拟机,从而实现加速
模拟测试
代码仓库:https://github.com/muchengl/userfault-test.git
编写代码进行模拟测试,本代码分为Server端和Client端。Server端对应Memory Node,Client端对应Running Node。
Server端使用malloc申请内存,并进行初始化。Client端使用mmap初始化内存,将fd参数设置为-1,从而获得大量未被映射的内存。并将这些内存标记为UFFD_EVENT_PAGEFAULT,即内核应将该内存的Page fault交给用户处理。Client端开启一个fault触发线程,不断按顺序access page,触发page fault。client端监听描述符uffd,获取内核传来的user fault信息,并通过udp协议,从server端获取相应的page,进行内存初始化。
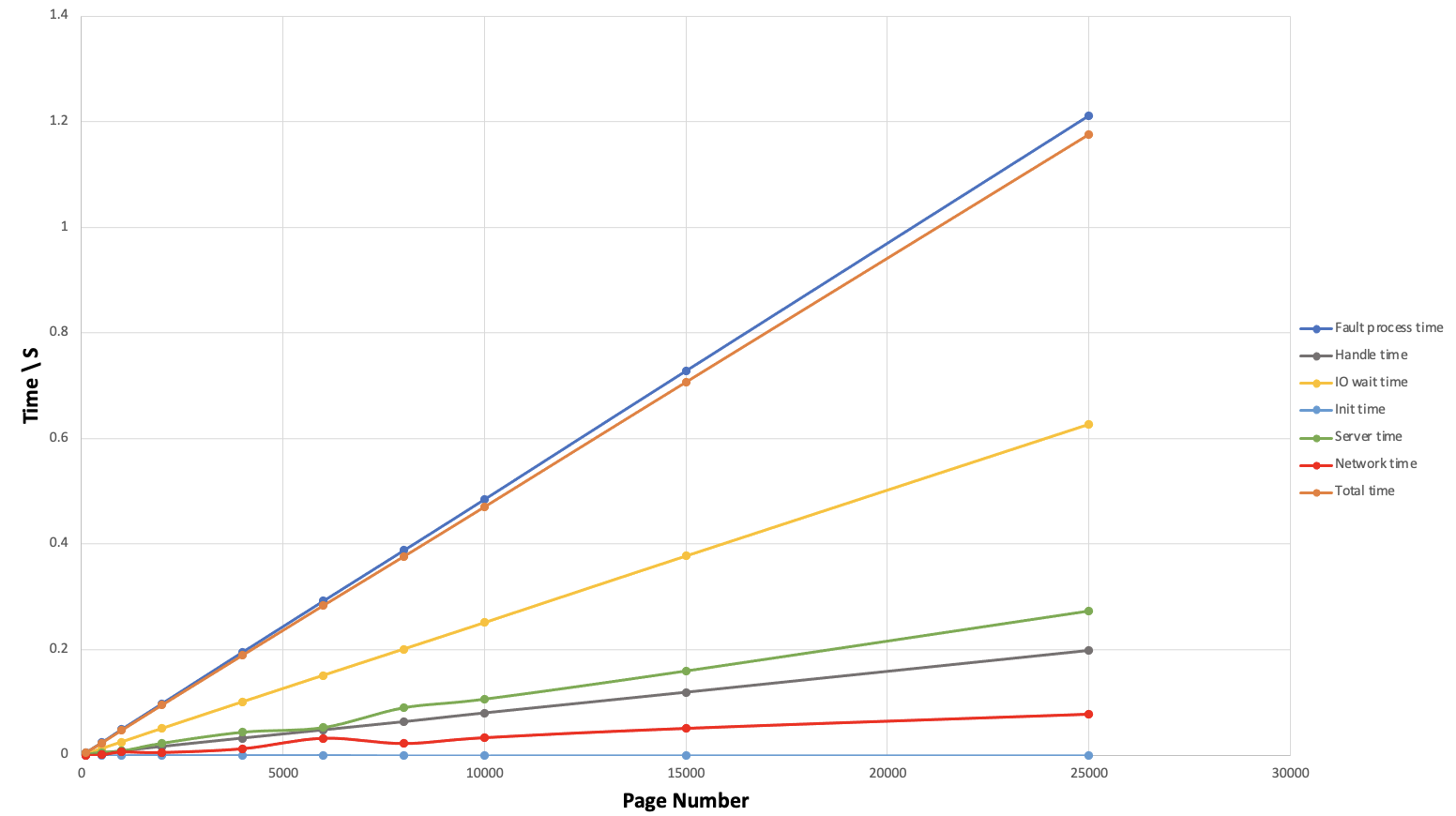
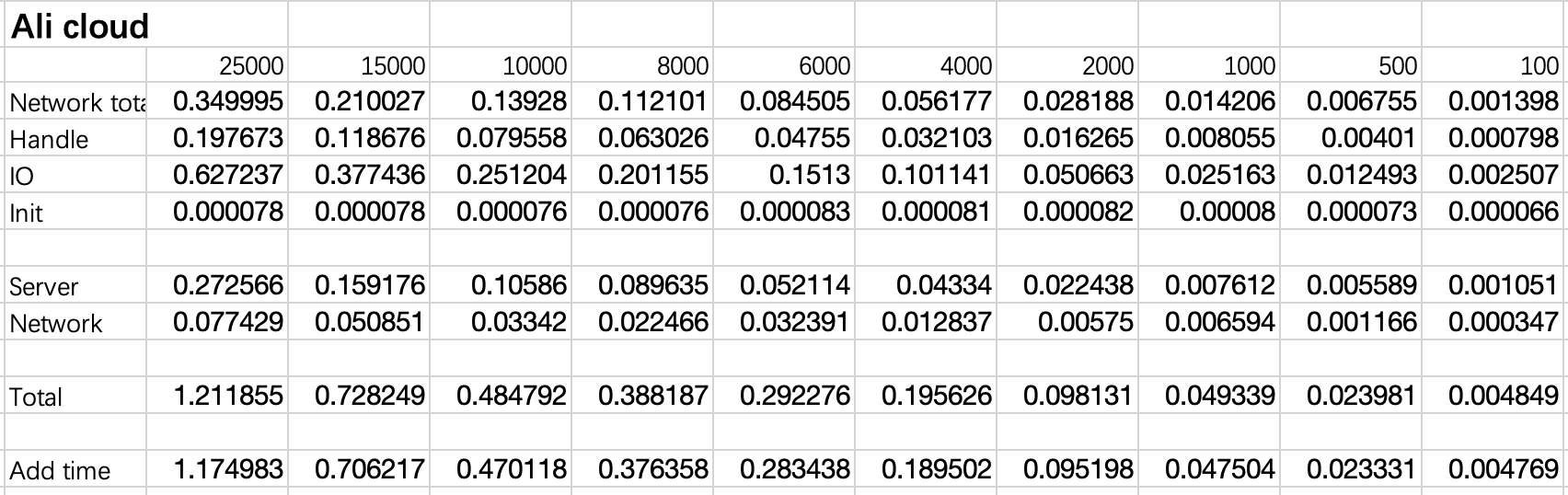
在两台Ali Cloud云服务器之间进行测试,Ununtu 20.04系统,1G内存,2核CPU,在同一虚拟子网内使用UDP进行数据传输,每组测量进行10次,取CPU运行时间的平均值。可以发现,远程拷贝总时间与页数呈正比。在拷贝内存为100M时(25000页),较优情况下需要约0.97秒的时间。
| 字段名称 | 含义 |
|---|---|
| Fault process time | Fault触发线程的总运行时间,也就是负载代码的实际运行时间 |
| Init time | Client端初始化时间 |
| IO time | 等待内核通过fd传输User Fault相关信息的时间(poll轮询) |
| Network time | UDP协议通信时间 |
| Server time | Server端获取page,并通过UDP发送的时间 |
| Handle time | 获取到远程页后,初始化内存,并对远程页中的数据进行拷贝的时间 |
| Total time | Total time=Network + Server + Handle + IO + Init 用于证明Network、Server、Handle、IO、Init可代表整个运行流程 |
经计算:Fault process time ≈ Total time
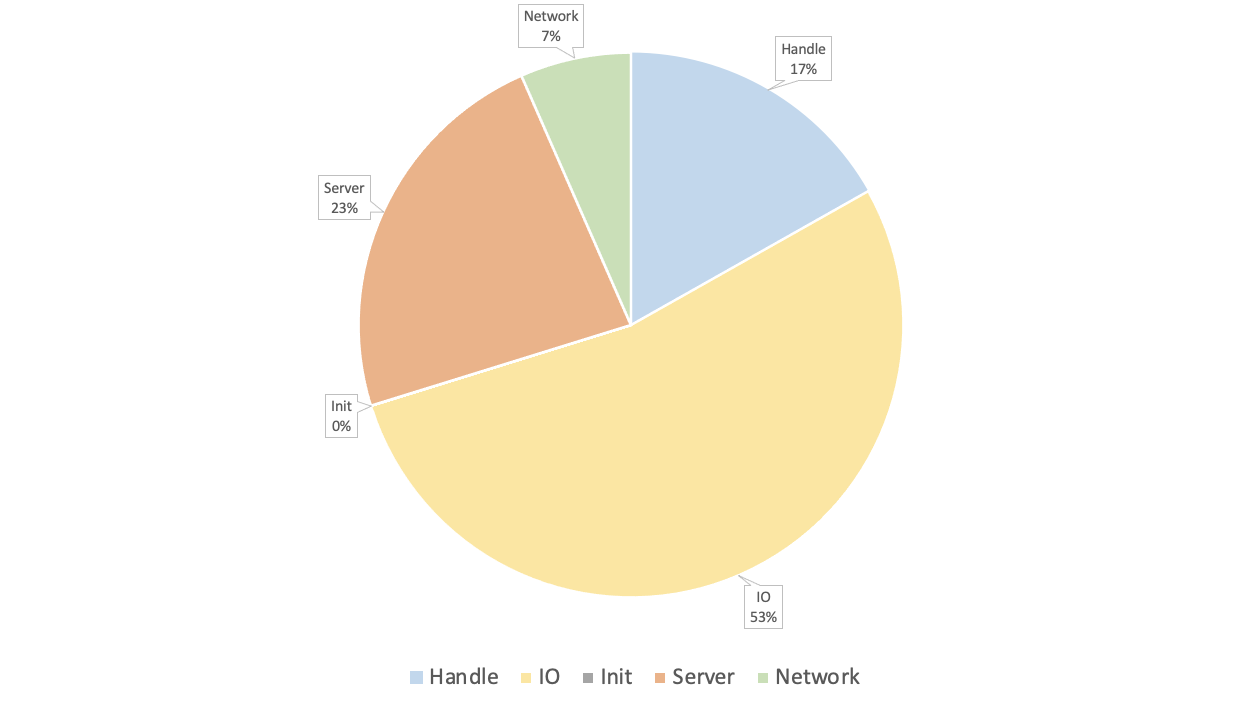
数据分析和总结:
Network占用了约7%的时间,真实环境下由于不会使用UDP,这一时间占比可能会更大。
IO time占比较大,为53%,这一时间在本地虚拟机测试中显著降低,因此或与CPU性能有较大关系。
(本测试中,使用的是阿里云的玩具级服务器,cpu主频和内存读写速度可能被限制了)
数据读取和拷贝部分(Server、Handle),占用了40%左右的时间。对比MITOSIS,misosis使用rdma避免了在server端的内存拷贝,因此会慢于misosis。
本测试中,测试负载为“按顺序访问内存”,这一测试与真实环境有较大区别,因此不能代表将Postcopy实际引入wasm后的实际性能。
附数据:
资料收集
User space page fault handling相关早期文章:
https://lwn.net/Articles/550555/
https://lwn.net/Articles/615086/
Postcopy原始论文:
https://kartikgopalan.github.io/publications/hines09postcopy.pdf
CRIU Lazy migration:
https://www.researchgate.net/publication/328214412_Efficient_Live_Migration_of_Linux_Containers
https://criu.org/Lazy_migration
https://lisas.de/~adrian/pdf/lazy-process-migration.pdf
Postcopy在kvm的应用:
https://www.jstage.jst.go.jp/article/imt/7/2/7_614/_pdf/-char/ja
RedHat在KVM迁移中的实践ppt:
http://events17.linuxfoundation.org/sites/events/files/slides/kvmforum2014.pdf
https://wiki.qemu.org/Features/PostCopyLiveMigration

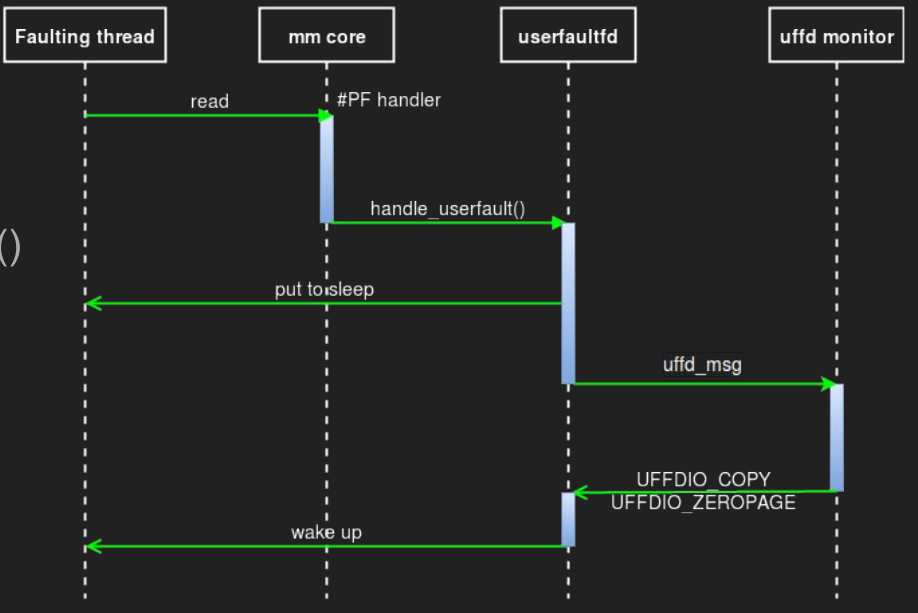
- 线程1访问了一个未被映射的page,发生userfault
get_user_pages_locked()
get_user_pages_unlocked()
这两个函数可以避免内核处理fault,而是交给用户线程处理 - 线程2收到内核的通知——userfault在某个地址被触发了
- 线程2将此page从“memory node”传输过来(这和mitosis的“seed”很类似)
- 线程2将发生错误的page进行映射
remap_anon_pages() - 线程2告知内核,内核唤醒线程1
- 线程1尝试访问fault page,并继续执行下去
Ubuntu对userfaultfd的支持
https://manpages.ubuntu.com/manpages/bionic/man2/userfaultfd.2.html